Machine Learning Modelling for Imbalanced Dataset: Case Study of Adolescent Obesity in Malaysia
DOI:
https://doi.org/10.37934/araset.36.1.189202Keywords:
Prediction, Adolescent obesity, Imbalanced datasetAbstract
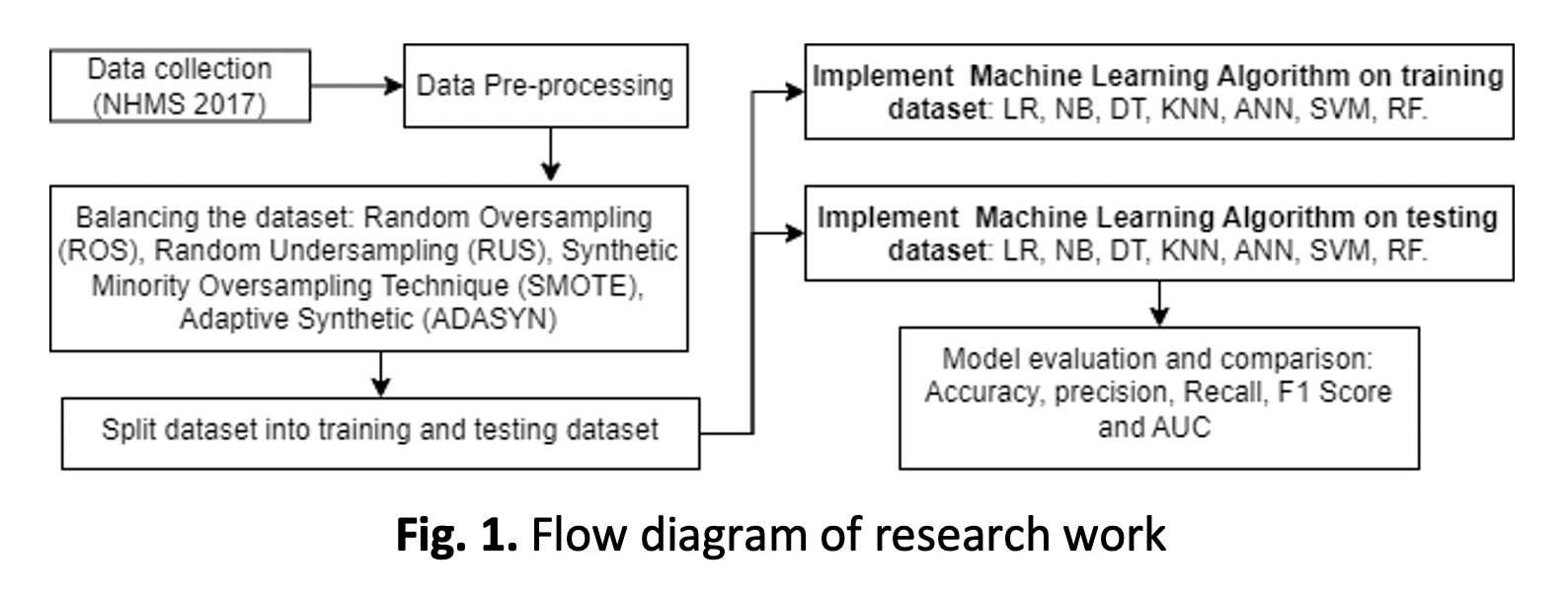
Obesity among adolescent is a public health issue with increasing burden of disease. Predicting imbalanced health data with Machine Learning may introduce bias and lead to diminished model performance. Misclassification in healthcare data could lead to misdiagnosing a patient or failing to detect a health issue when it is present. The purpose of this study is to predict adolescent obesity using machine learning along with implementation of multiple approaches on the imbalanced dataset. This study used secondary dataset from National Health and Morbidity Survey 2017. Samples 13 – 17 years were selected for the classification. SPSS V26 was used for data pre-processing, data cleaning, and data analysis. Meanwhile, Python language used for prediction and evaluation of the models. Approaches on the imbalanced dataset including resampling method (Random Oversampling, Random Under-sampling) and hybrid method (SMOTE and ADASYN) were implemented. This dataset was used for the formation of predictive models on ML algorithm including Artificial Neural Network, Decision Tree, K-Nearest Neighbour, Logistic Regression, Naïve Bayes, Random Forest and Support Vector Machine. The performance of each model was evaluated and compared using accuracy, precision, recall, F- score and Area under the Curve (AUC). Random Oversampling approached with Decision Tree Algorithm performs the best with accuracy (91.35%), precision (0.93), recall (0.91), F- score (0.91) and AUC (0.91) for the prediction of obesity among adolescent in Malaysia. The presented ML model development workflow along with the imbalanced techniques can be adapted to other health survey-based studies and may be valuable for developing other clinical prediction models.