WCA: Integration of Natural Language Processing Methods and Machine Learning Model for Effective Analysis of Web Content to Classify Malicious Webpages
DOI:
https://doi.org/10.37934/araset.47.1.105122Keywords:
Count, Term frequency and inverse document frequency, Machine learning model, Phishing, Malicious webpagesAbstract
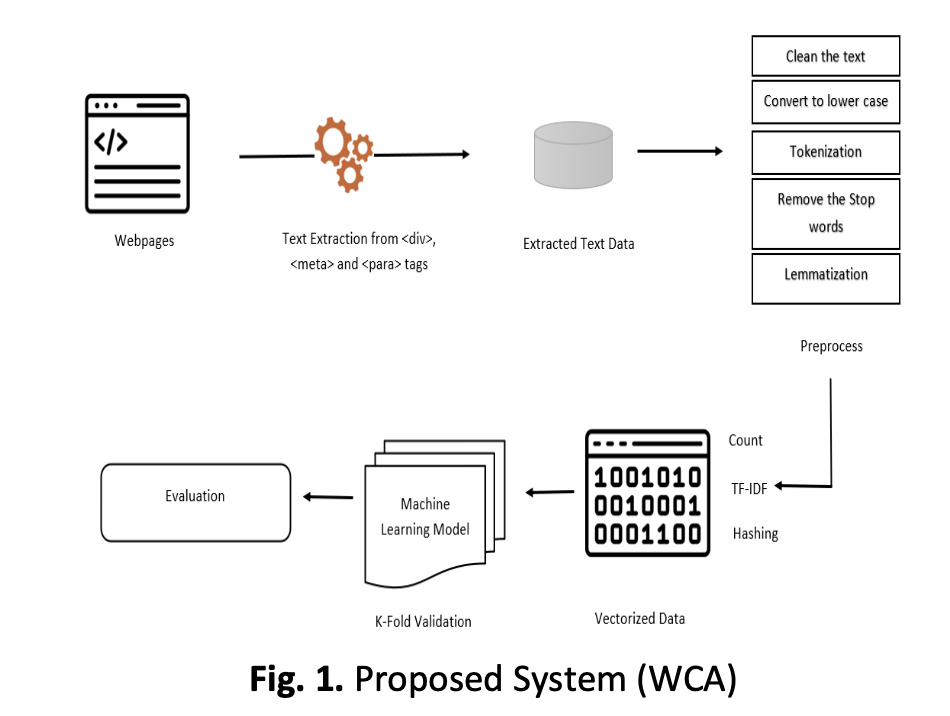
Malicious websites have become a pervasive concern in the digital realm, targeting careless users as well as organizations. It may result in substantial financial losses, identity theft, data intrusions, and damage to reputation. In order to create efficient countermeasures, it is crucial to comprehend the effects of interacting with such websites. There are several ways to classify malicious webpages. Web content analysis is one such way for protecting internet users from malicious activities. It entails analysing websites to identify potential hazards, such as phishing attempts, malware distribution, and fraudulent activities. Traditional methods relied on rule-based systems, but recent advances in natural language processing and machine learning have opened up new avenues for increasing the precision and scalability of web content analysis to classify malicious webpages. Most of the exciting research work focuses more on URL alone for risk free processing. This paper introduces novel method for analysing web contents especially textual contents of the webpages for classification. Among various tags in web technology, proposed method focuses on div, paragraph and meta tags. The textual contents of these tags are extracted and vectorized using three different vectorizers in natural language processing and classify the webpages using machine learning models. Seven different machine learning models are used for performance evaluation. The result shows that a combined textual content of three distinct tags with count vectorizer + random forest achieves the higher accuracy of 93.46% with 1000 features.