Adopting Text Mining for Patent Analysis to Determine the Attribute and Segment in Automotive Industries
DOI:
https://doi.org/10.37934/araset.37.2.94103Keywords:
Text mining, word cloud, co-occurrence networks, correspondence analysis, NLP, pre-processingAbstract
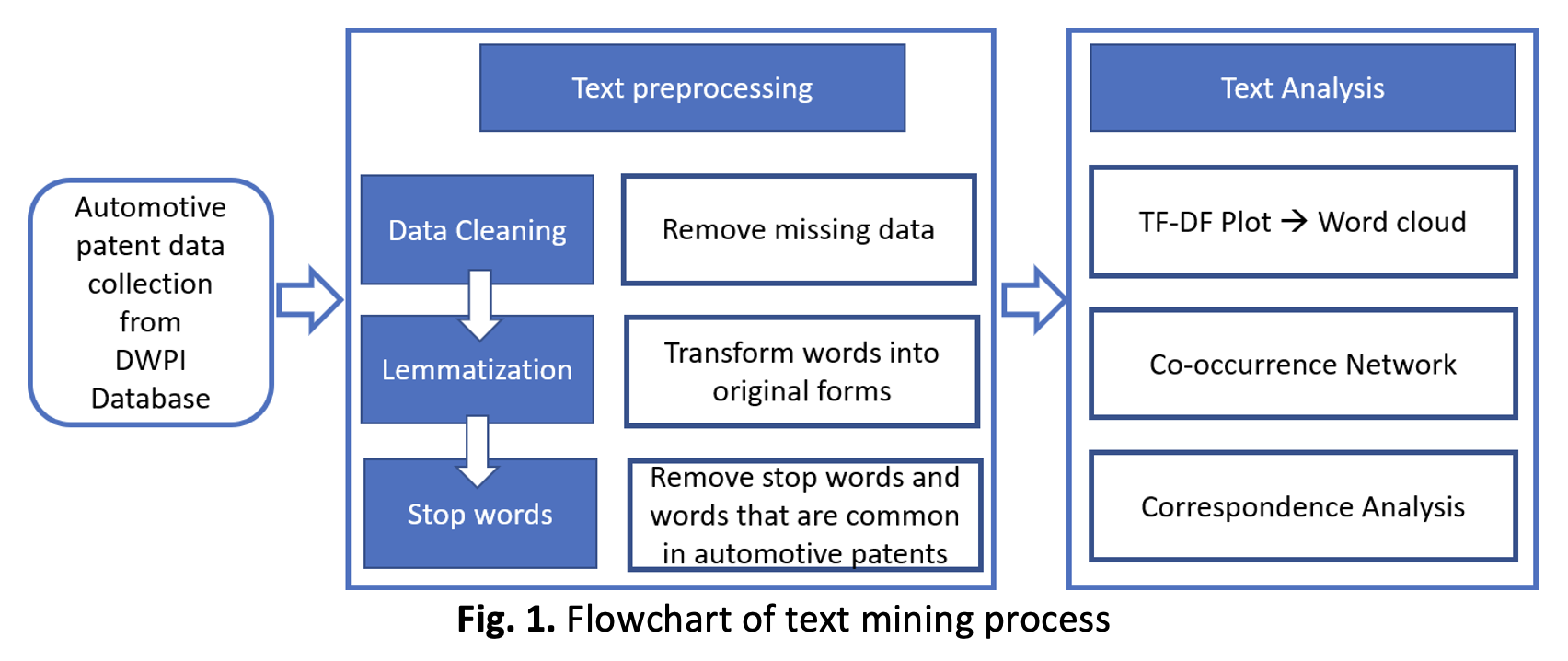
Analysing massive patent documents in heavy industries including automotive has become important in recent years as they contain a lot of information that is extremely difficult to deal with from huge numbers and various forms. Important documents such as patent data on a huge scale has become a major concern owing to time constraints and enormous costly work. In natural language processing (NLP), text mining is used to determine several features such as segmentations and attributes of data. The important step in data mining is pre-processing data information from massive text data. In this paper, the fundamental concept of pre-processing and data analysing is examined to provide accurate and meaningful information from the chosen data set. This study focuses on two automotive companies, namely Mazda and Mitsubishi to describe the similarities, distances and frequencies between several patent documents. To demonstrate the behaviour of selected patent documents, word cloud, co-occurrence networks and correspondence analysis are also presented.