
Instance Segmentation Evaluation for Traffic Signs
DOI:
https://doi.org/10.37934/araset.34.2.327341Keywords:
Instance Segmentation, Traffic Sign Recognition, YOLACT, Deep Learning Approach, Image SegmentationAbstract
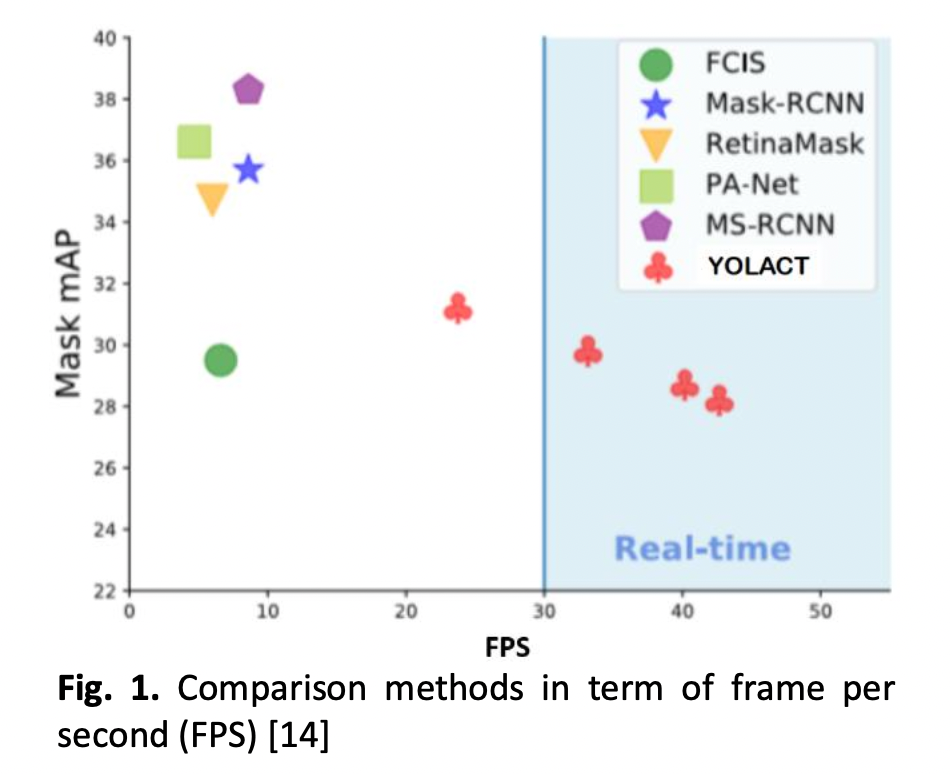
This research paper focuses on developing a traffic sign recognition system based on the You Only Look At Coefficients (YOLACT) model, a one-stage instance segmentation model that offers high performance in terms of accuracy and reliability. However, the performance of YOLACT is influenced by various conditions such as day/night and different angles of objects. Therefore, this study aims to evaluate the impact of different angles and environments on the performance of the system. The paper discusses the framework, backbone structure, prototype generation branch, mask coefficient, and mask assembly used in the system. ResNet-101 and ResNet-50 were used as the backbone structure to extract feature maps of objects in the input image. The prototype generation branch generates prototype masks using fully convolutional networks (FCN), and the mask coefficient branch generates the Mask assembly using the sigmoid nonlinearity. Two models, YOLACT and Mask-RCNN, were evaluated in terms of mean precision (mAP) and frames per second (FPS) with the front view dataset. The results show that YOLACT outperforms Mask-RCNN in terms of accuracy and speed. For an image resolution of 550x550, YOLACT with Resnet-101 was considered the best model in this article since it achieves over 80% precision, recall, specificity, and accuracy in various conditions such as day, night, left and right, and forward-looking angles.
Downloads
Downloads
Published
How to Cite
Issue
Section


























